New York Times API Tutorial
Le API del New York Times offrono la possibilità di sviluppare applicazioni capaci di interagire con i contenuti del celebre quotidiano statunitense, consentendo l’accesso a un vasto archivio di articoli, il recupero di metadati sulle pubblicazioni e l’ottenimento di aggiornamenti in tempo reale sulle notizie più rilevanti.
Grazie a queste API, gli sviluppatori possono creare applicazioni in grado di effettuare ricerche avanzate tra gli articoli del giornale, accedere a recensioni e classifiche dei best seller, esplorare contenuti multimediali e analizzare i trend dell’informazione.
Sommario
- Preambolo
- Introduzione
- Configurazione ambiente
- Accesso alle API
- Utilizzo delle API RESTful
- API New York Times Python: pynytimes
- Estrazione dei dati e analisi
- Conclusioni
- Referenze
Preambolo
Il The New York Times è un giornale statunitense fondato il 18 settembre 1851 dal giornalista e politico Henry Jarvis Raymond e dall'ex banchiere George Jones con il nome New York Daily Times, che sarà modificato sei anni dopo nell'attuale The New York Times. L'obiettivo dei fondatori era quello di creare un giornale cittadino che riportasse le notizie in maniera oggettiva, discostandosi dal sensazionalismo tipico delle testate della Grande Mela.
The New York Times raggiungerà una diffusione internazionale solo dopo il 1896, anno in cui l’editore Adolph S. Ochs acquistò il giornale. A lui si deve lo slogan "All the News That's Fit to Print", comparso per la prima volta il 25 ottobre 1896.
In un articolo pubblicato il 22 gennaio 1996 si legge "The New York Times Introduces a Web Site": in quell'anno, infatti, il giornale si apre a un nuovo ambiente in cui pubblicare e diffondere le proprie notizie, il World Wide Web. Il sito web, raggiungibile all’indirizzo www.nytimes.com, consente un accesso immediato alle informazioni offerte da una testata autorevole. Oltre a ciò, il sito e l'app mobile (lanciata nel 2008) offrono una vasta gamma di contenuti multimediali, come reportage interattivi, podcast e video di approfondimento. Un’altra caratteristica della versione online è la distinzione tra articoli gratuiti e contenuti premium, nonché la possibilità, per gli abbonati, di accedere a contenuti personalizzati e raccomandati in base agli interessi degli utenti. È infatti possibile salvare gli articoli, condividerli e ricevere notifiche.
Introduzione
Le API messe a disposizione gratuitamente dal The New York Times online permettono di accedere ai contenuti e ai dati del giornale per creare applicazioni in grado di interagire con articoli, sezioni, recensioni e altri elementi pubblicati dal NYT.
Attualmente il sito offre dieci API pubbliche: Archive API, Article Search API, Books API, Most Popular API, Movie Reviews API, RSS Feeds, Semantic API, Times Wire API, Times Tags API e Top Stories API. Per saperne di più, puoi consultare la documentazione ufficiale delle API del New York Times.
Questo tutorial illustrerà i passaggi necessari per accedere alle API pubbliche del New York Times utilizzando Python e le sue principali librerie. Verrà inoltre condotta un'analisi descrittiva dei dati, con l’obiettivo di mostrare quali tipi di ricerche sia possibile effettuare partendo dalle informazioni fornite tramite le API.
Configurazione ambiente
Prima di iniziare, può essere utile creare un ambiente virtuale per lavorare al progetto. E' possibile creare un ambiente virtuale utilizzando 'virtual env' o 'conda'. Se vuoi saperne di più su come creare un ambiente virtuale utilizzando virtual env clicca qui.
In questo tutorial, useremo conda come esempio:
Se non hai installato conda, puoi installare Miniconda o Anaconda.
Dopo aver installato conda, apri il terminare e crea un nuovo ambiente virtuale lanciando il seguente comando:
conda create --name myenv python=3.9
Per attivare l'ambiente, usa il comando:
conda activate myenv
Per disattivare l'ambiente:
conda deactivate
Puoi sostituire myenv con il nome che preferisci per il tuo ambiente virtuale.
La creazione di un ambiente virtuale in Python è una pratica necessaria per garantire l'isolamento del progetto rispetto ad altri sviluppi, evitando conflitti tra diverse versioni di pacchetti e librerie.
Un ambiente virtuale crea uno spazio indipendente in cui installare le librerie necessarie, senza interferire con le configurazioni globali di Python o con altri progetti. Questo è particolarmente utile quando si lavora su applicazioni che richiedono versioni specifiche di moduli o framework, evitando incompatibilità che potrebbero comprometterne il funzionamento.
Accesso alle API
Creazione del profilo utente
Per accedere alle API del New York Times è necessaria una API key ottenibile solo dopo la registrazione dell’utente al sito e la creazione di un’applicazione.
Il primo passo consiste nella creazione di un profilo utente.
Dopo la registrazione, verrà visualizzata la seguente schermata:
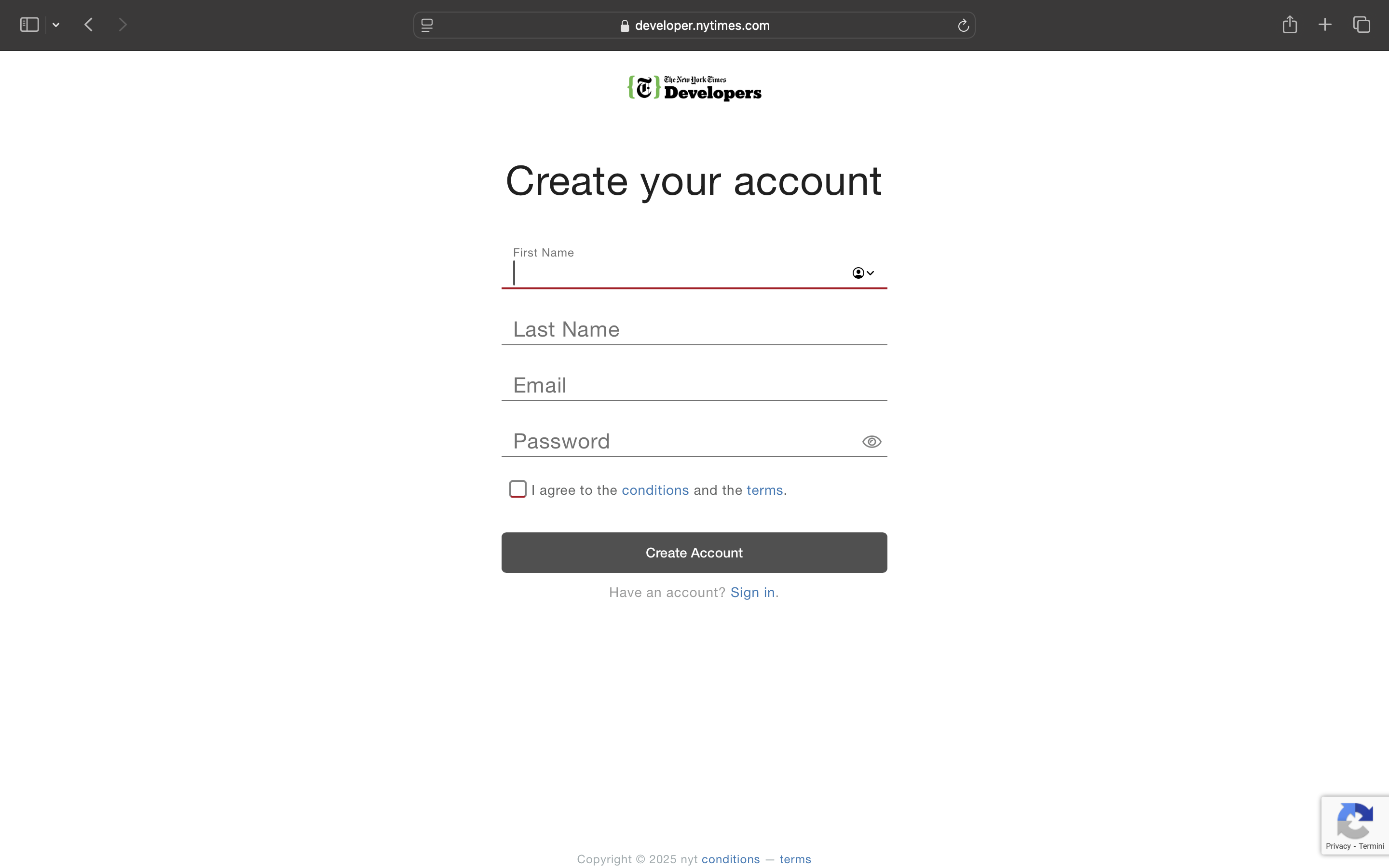
A questo punto, sarà sufficiente inserire i dati richiesti, cliccare su Create Account e attendere l’email di verifica che verrà inviata all’indirizzo specificato.
Dopo aver verificato l’account, sarà possibile accedere al proprio profilo:
Dopo aver effettuato l'accesso, verrà visualizzata la seguente schermata:
Creazione dell'applicazione
Per richiedere una API key e accedere alle API è necessario creare un’applicazione. Clicca sul menù a tendina in alto a destra e seleziona la sezione Apps:
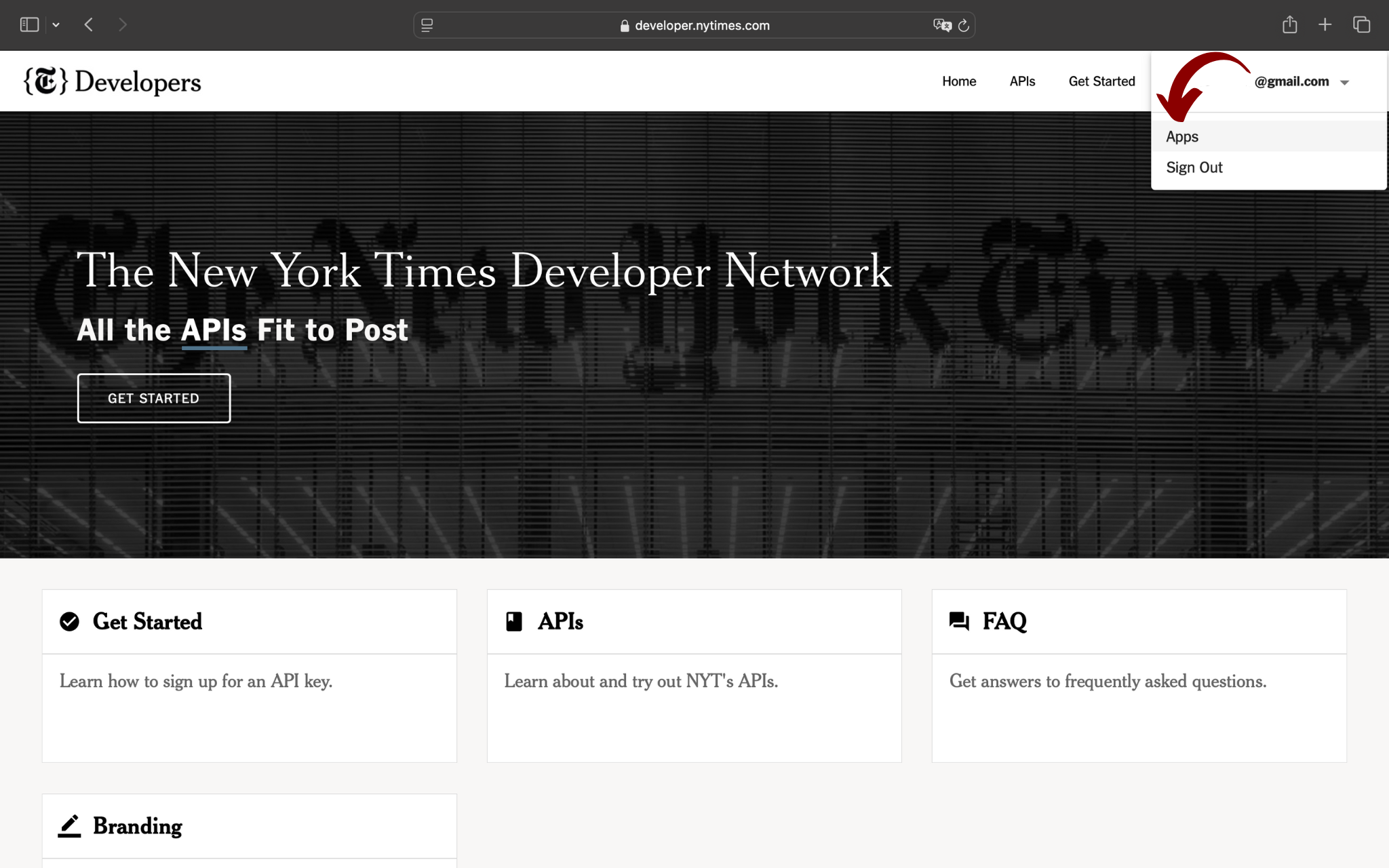
Ora clicca sul pulsante New Apps per creare la tua applicazione:
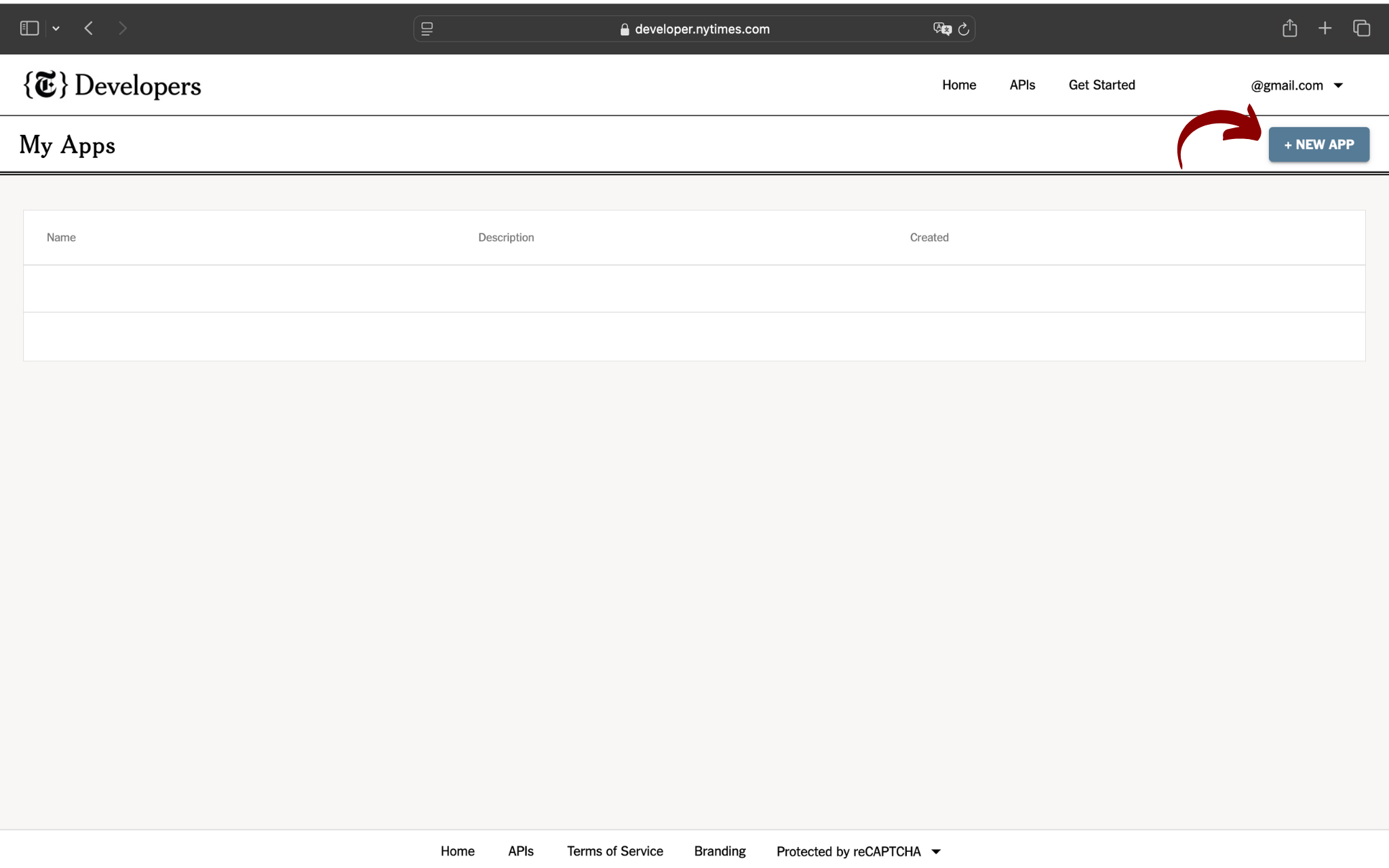
Dopo aver cliccato sul pulsante New apps verrà visualizzata una schermata in cui ti verrà chiesto di inserire un nome per l'applicazione e una breve descrizione:
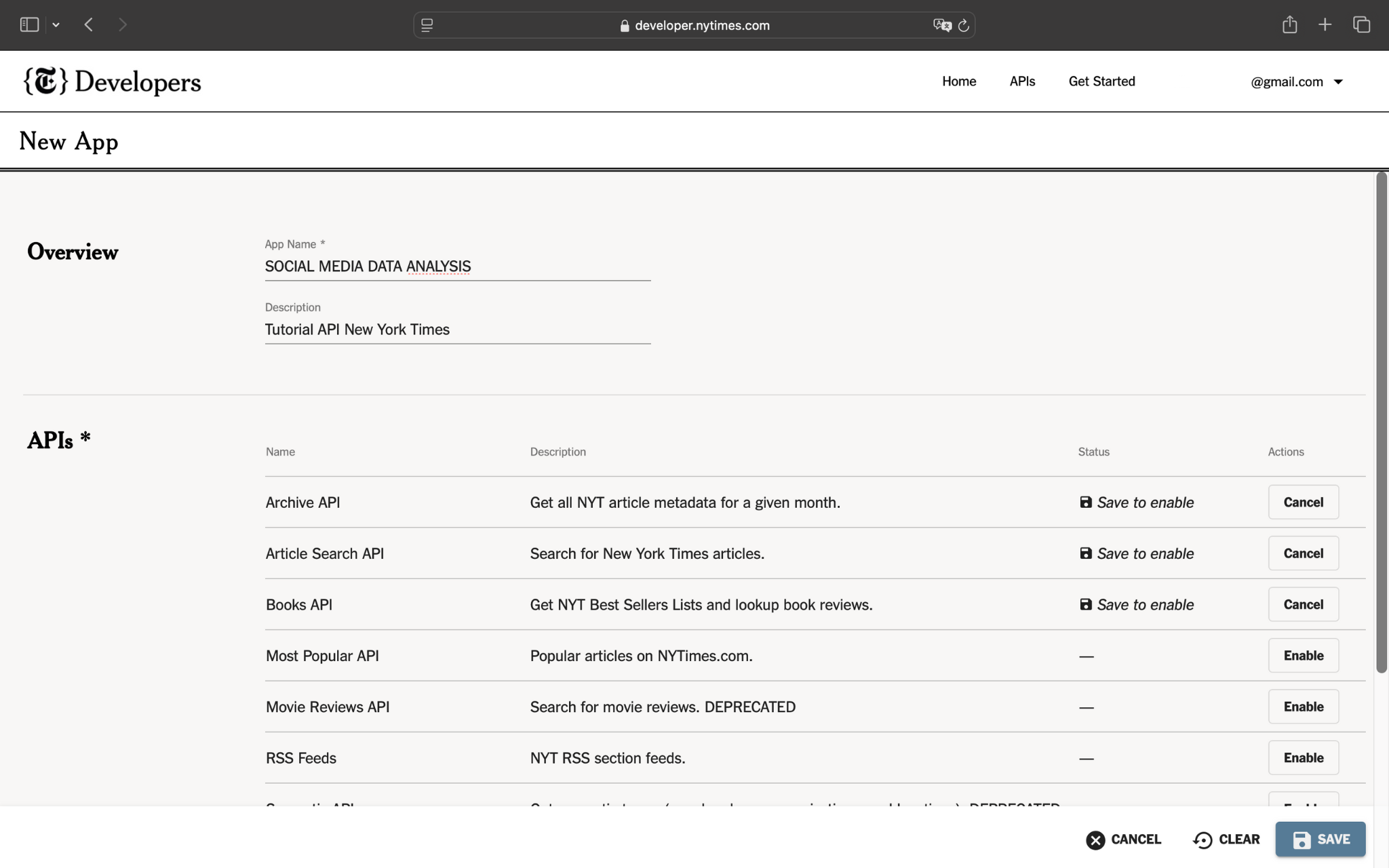
Una volta inseriti i dati richiesti, avrai accesso alla tua applicazione, nonché alla tua API Key e alla tua API Secret:
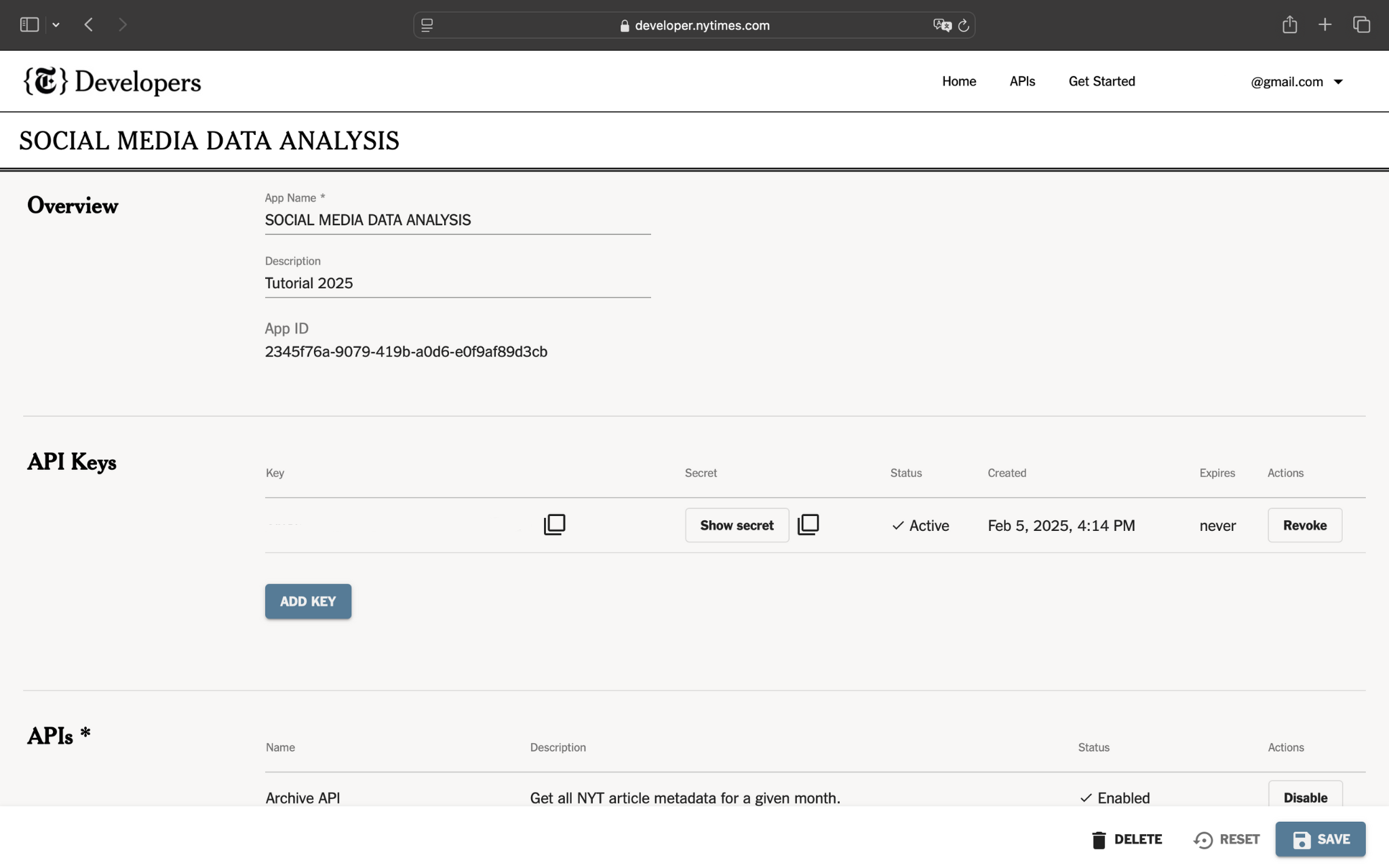
Utilizzo delle API RESTful
Di seguito verrà mostrato del codice Python utile per accedere alle API del New York Times e raccogliere dati. Verrà illustrata l'architettura RESTful tramite un esempio pratico e saranno mostrati 3 esempi di accesso e utilizzo delle API.
Per ottenere i dati dalle API viene utilizzata l'architettura REST (Representational State Transfer), che definisce le modalità di accesso e manipolazione dei dati.
L'architettura REST si basa sui seguenti principi:
- Separazione tra client e server, che comunicano tra loro tramite il protocollo HTTP;
- Accesso ai dati tramite i metodi HTTP
get,post,put,delete; - Richieste stateless: ogni richiesta è indipendente e deve contenere tutte le informazioni necessarie affinché il server possa elaborarla;
- I dati restituiti sono generalmente in formato
JSON.
Nei paragrafi successivi verranno mostrati esempi pratici di accesso alle API utilizzando l’architettura REST.
Top Stories API
Per accedere alle API del New York Times, a differenza di altre API che richiedono l'uso del protocollo OAuth, è sufficiente autenticarsi con la propria API key, da inserire in una variabile all'interno del codice.
Se l'applicazione sviluppata dovesse essere venduta o pubblicata online, è fondamentale non includere la propria API key all'interno del codice, trattandosi di una chiave di autenticazione segreta.
È consigliabile creare un file .env in cui salvarla e successivamente importarla nel codice utilizzando la libreria python-dotenv, che consente la lettura dei file .env, insieme al modulo os per accedere al valore della variabile d'ambiente.
Il codice seguente mostra come accedere alla Top Stories API, che consente di ottenere gli articoli presenti nella homepage. Il codice è molto semplice: ho limitato le informazioni estratte per ogni articolo al titolo e all'URL, al fine di mostrare il funzionamento del codice e renderne la lettura più agevole.
import requests # importiamo requests, libreria necessaria per effettuare richieste HTTP
API_KEY = "inserisci la tua api-key" # inizializziamo una variabile con la nostra api key
url = f"https://api.nytimes.com/svc/topstories/v2/home.json?api-key={API_KEY}" # inizializziamo una variabile con l'url dell'API e utilizzando
# il metodo f-string (formattazione della stringa) inseriamo la variabile contenente la nostra chiave tra parentesti graffe assieme all'url
response = requests.get(url) # eseguiamo la richiesta GET
if response.status_code == 200: # controlliamo se la richiesta ha avuto successo (status code 200)
data = response.json() # converte la risposta ottenuta in formato JSON
articles = data['results'][:10] # creiamo una variabile che raccoglie gli articoli e chiediamo di ottenere i primi 10
for i, article in enumerate(articles): # iteriamo in articles e indichiamo le informazioni che vogliamo ottenere:
title = article['title']
url = article['url']
print(f"{i+1} - {title} {url}") # visualizziamo a schermo, numerati (partendo da 1), il titolo e l'url dei primi 10 articoli della sezione
# home dell'API 'top stories'
else:
print(f"Errore: {response.status_code}") # se la richiesta dovesse fallire, visualizziamo a schermo l'errore
1 - With Trump Visit, Qatar’s Image Makeover Scores Another Success https://www.nytimes.com/2025/05/14/world/middleeast/trump-qatar.html 2 - A Loyal Ally Joins Trump’s Gulf Tour: The Head of Global Soccer https://www.nytimes.com/2025/05/14/world/middleeast/trump-fifa-world-cup.html 3 - Qatar Woos Trump, and Israeli Officers Privately Admit Gazans Near Starvation https://www.nytimes.com/2025/05/14/podcasts/the-headlines/trump-qatar-syria-gaza-starvation.html 4 - Beyond Tariff Truce, China Readies for a Rocky Time With U.S. https://www.nytimes.com/2025/05/14/world/asia/china-us-tariffs-security.html 5 - 185% Tariffs: How the Trade War Hit One Shipment of T-Shirts https://www.nytimes.com/interactive/2025/05/14/business/economy/trump-china-tariffs-import-goods.html 6 - What to Know About Trump’s Latest Changes to Taxes on Small Packages From China https://www.nytimes.com/2025/05/14/business/trump-tariffs-china-temu-shein.html 7 - In High-Stakes Negotiations, Trump’s Opponents Are Learning His Patterns https://www.nytimes.com/2025/05/13/us/politics/trump-ukraine-china-iran-negotations.html 8 - Menendez Brothers Resentenced to Life With Parole, Paving Way for Freedom https://www.nytimes.com/2025/05/13/us/menendez-brothers-resentenced.html 9 - Wisconsin Judge Indicted on Charges That She Helped Immigrant Evade Agents https://www.nytimes.com/2025/05/13/us/milwaukee-judge-hannah-dugan-immigration.html 10 - Inside the Extraordinary Contradictions in Trump’s Immigration Policies https://www.nytimes.com/2025/05/13/us/politics/trump-refugees-white-south-africa-aghanistan.html
Most Popular API
La Most Popular API restituisce gli articoli più popolari per uno specifico periodo di tempo (1 giorno, 7 giorni, 30 giorni). È possibile scegliere di ottenere gli articoli più visualizzati o gli articoli più condivisi su Facebook o tramite e-mail. Nella dimostrazione di seguito, estrarremo gli articoli più visti negli ultimi 7 giorni.
Prima di iniziare con il codice Python, è importante sapere che per questa API è necessaria un'autorizzazione aggiuntiva da richiedere sulla pagina dell'API, raggiungibile al seguente link:
Accedendo alla pagina, verrà visualizzata una schermata in cui, a sinistra, sarà possibile scegliere il path di interesse; nel nostro caso, selezioniamo /viewed/{period}.json che ci permette di accedere agli articoli più visti in un determinato arco temporale:
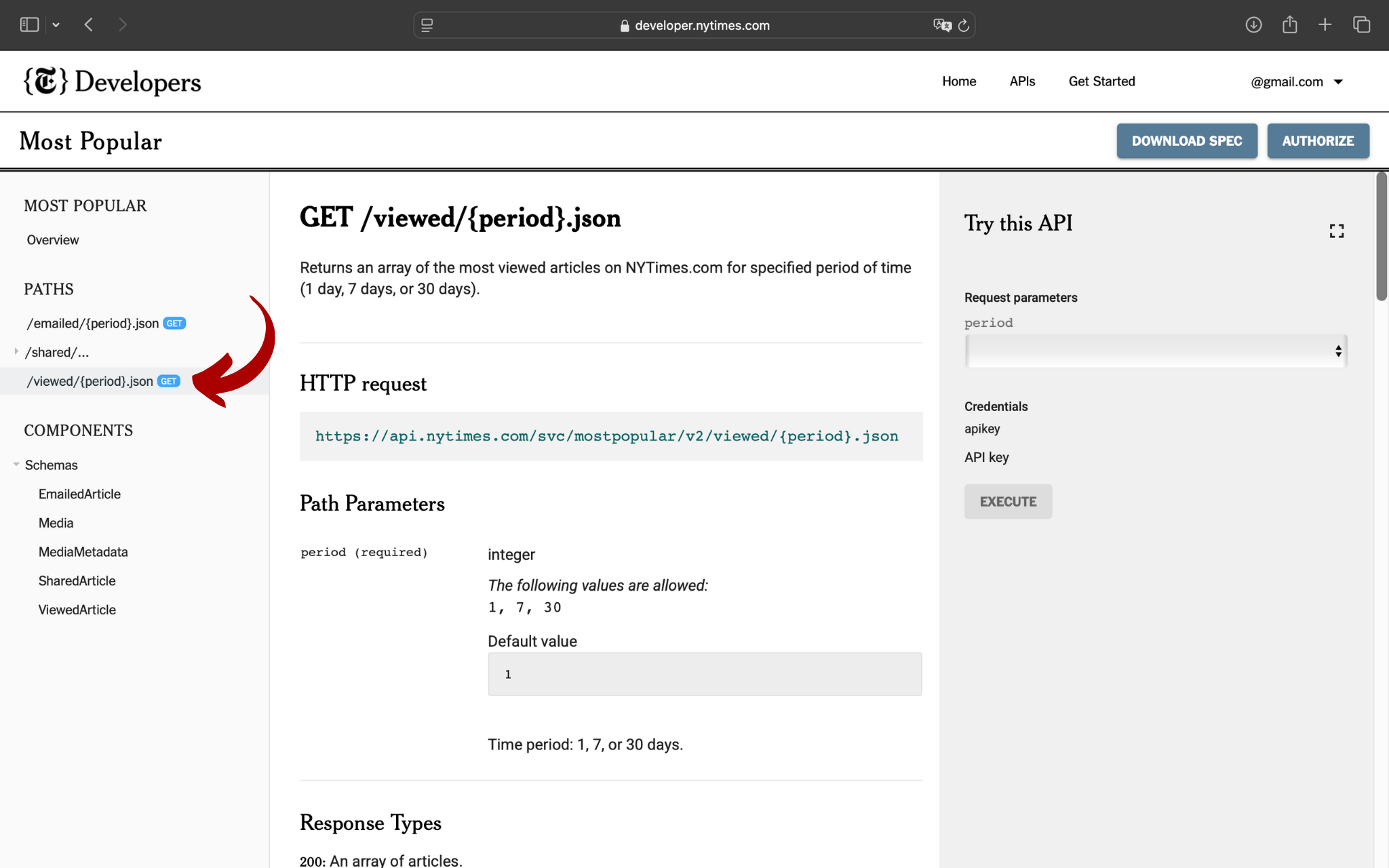
Nota il tasto DOWNLOAD SPEC, tramite il quale puoi scaricare le specifiche di questa API.
Adesso clicca su AUTHORIZE. Comparirà un pop up da compilare per ricevere l'autorizzazione di accesso:
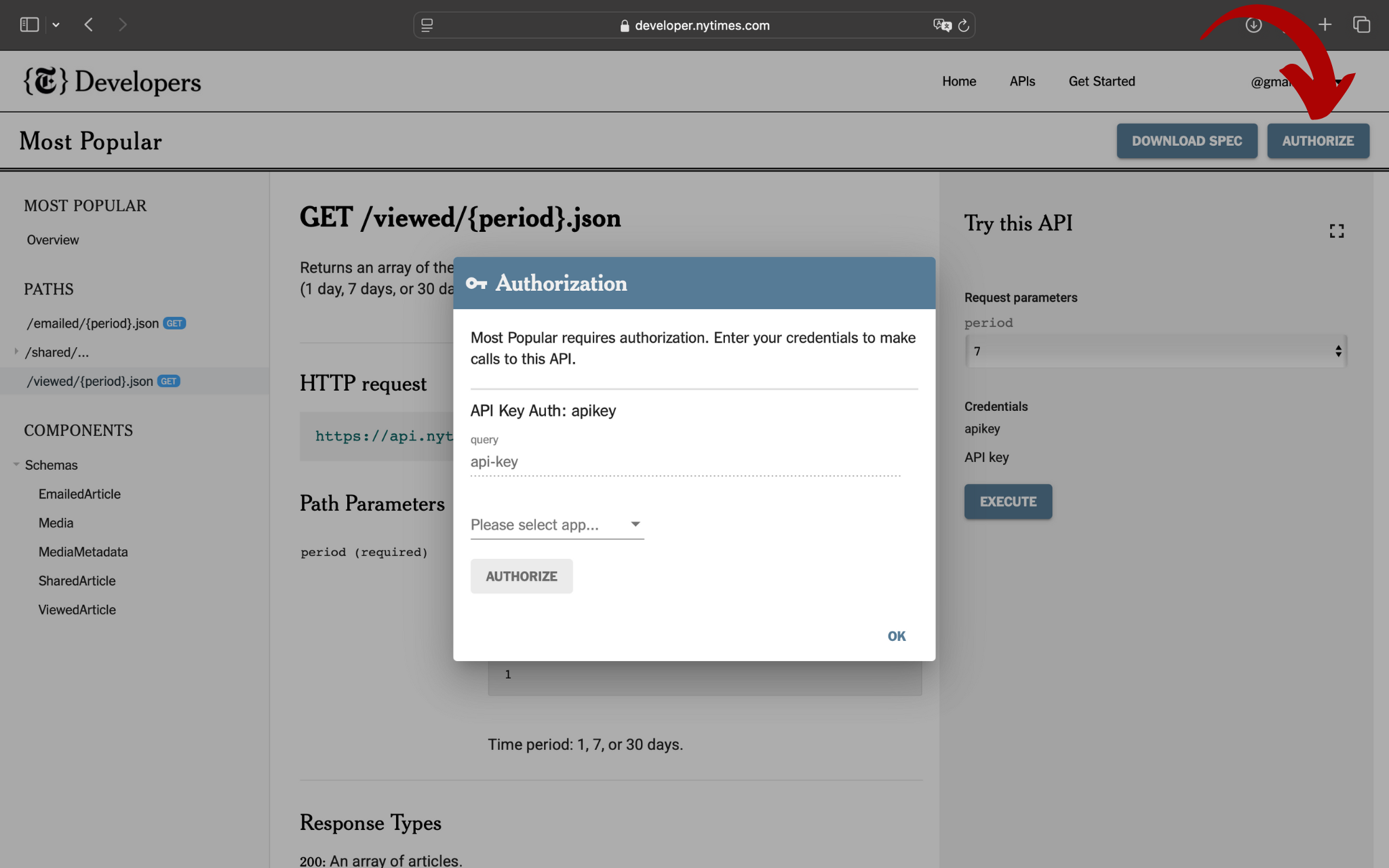
Cliccando sul menù a tendina, potrai scegliere se inserire manualmente la tua API key o selezionare la tua applicazione:
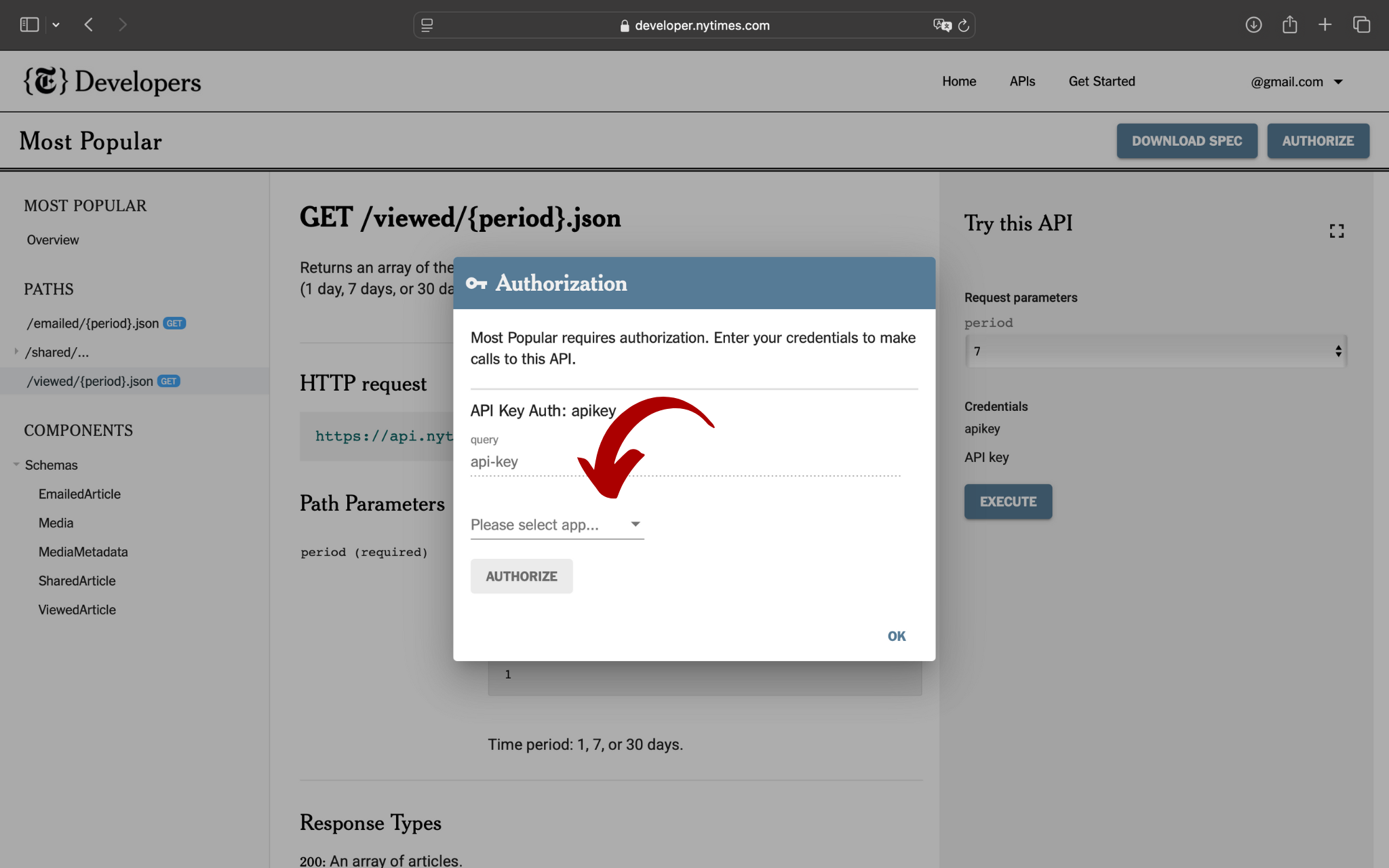
Dopo aver inserito i dati richiesti, basterà cliccare prima sul tasto AUTHORIZE e poi su OK:
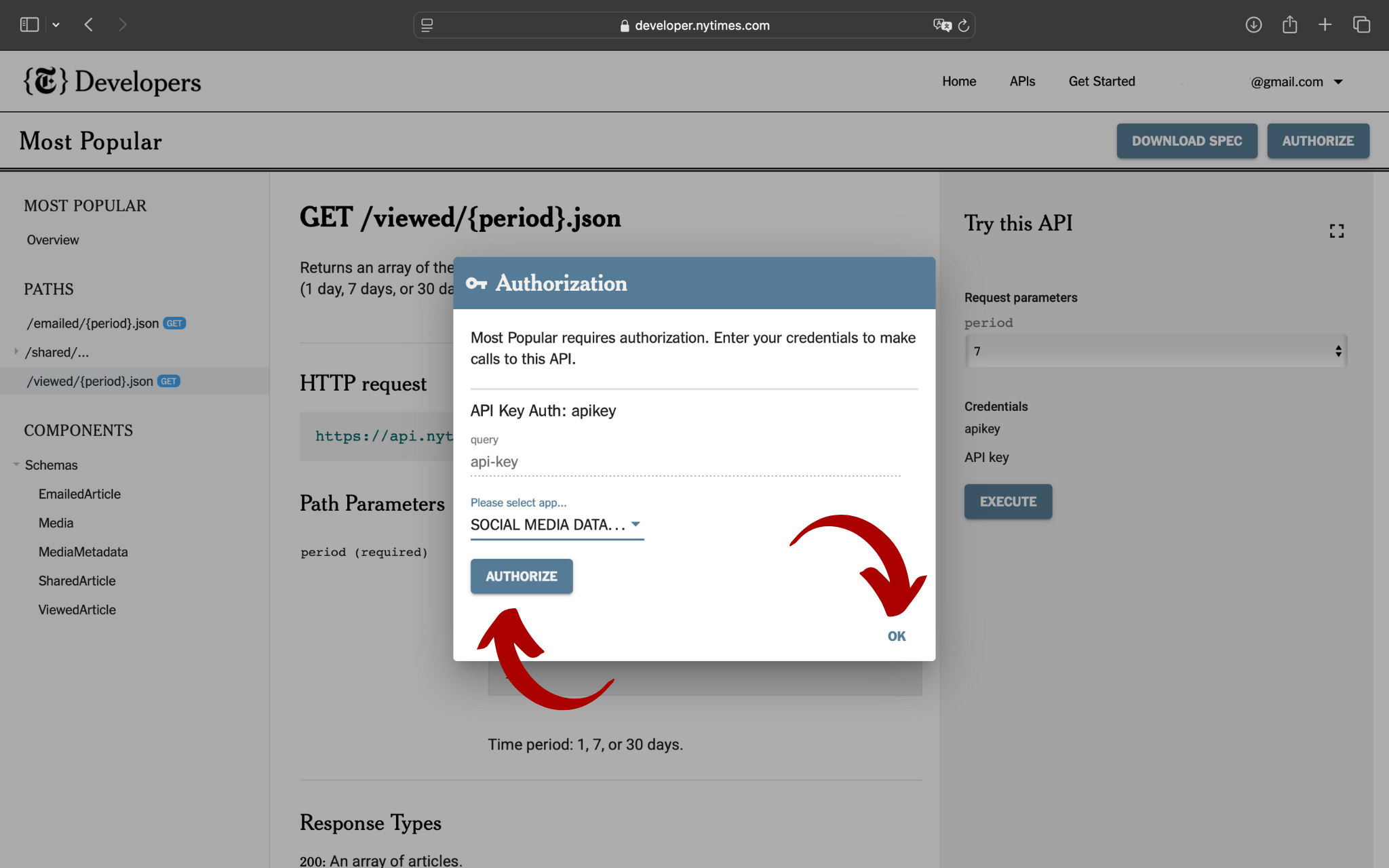
Ora, basterà compilare la colonna di destra dal titolo Try this API, inserire il parametro desiderato e cliccare su EXECUTE:
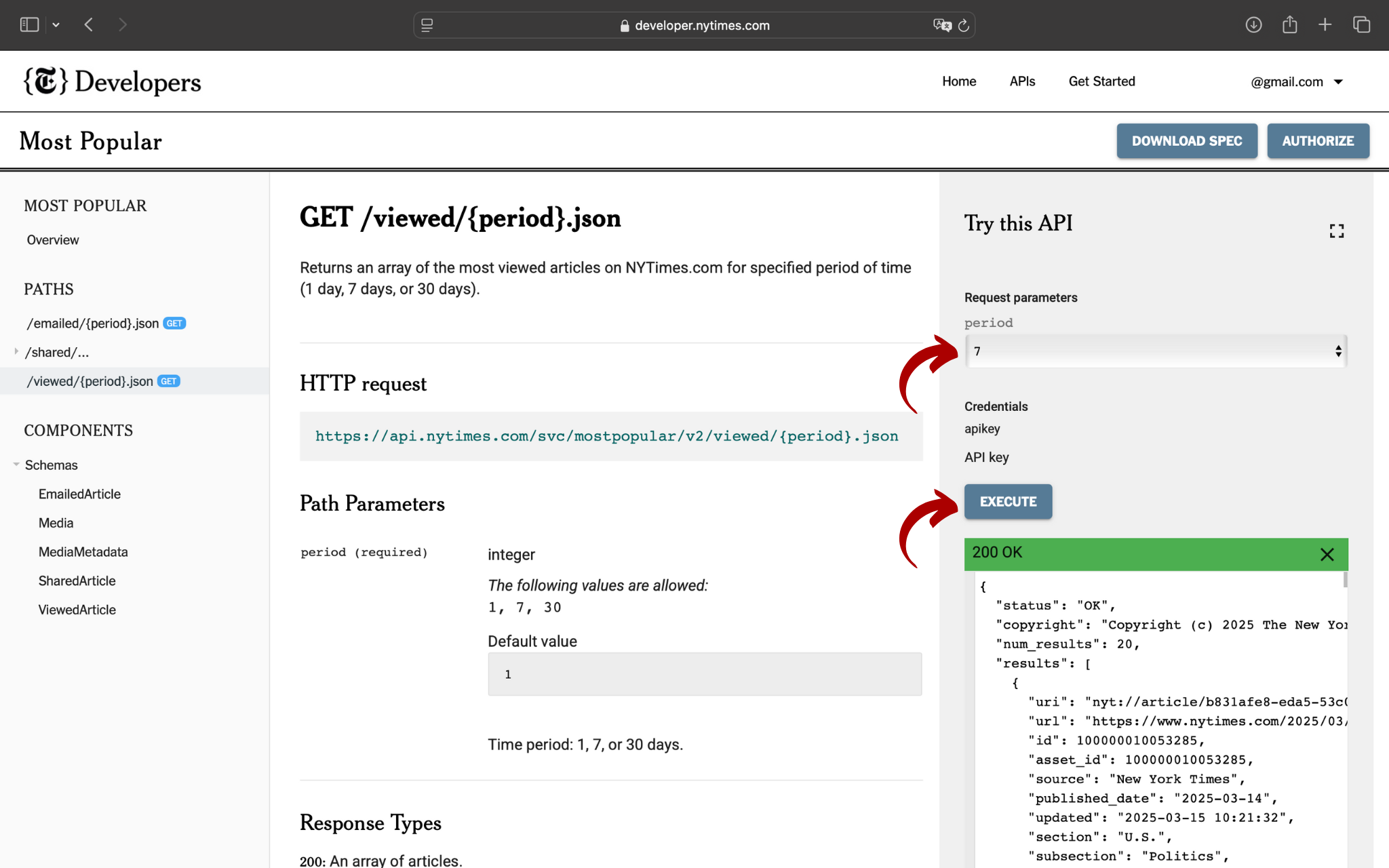
Se dopo aver eseguito la richiesta il risultato è come nell'immagine precedente - con il messaggio 200 OK in verde - l'operazione è andata a buon fine e puoi accedere alle API. Se dovessi visualizzare i codici di errore 401 o 421, ecco cosa fare:
- 401: Unauthorized request. Make sure API key is set. Prova a rieseguire la procedura indicata, potresti aver commesso qualche errore.
- 429: Too many requests. You reached your per minute or per day rate limit. In questo caso, bisogna semplicemente attendere.
import pandas as pd
# Abilitiamo la modalità "copy on write" di pandas per evitare avvertimenti di copia
pd.options.mode.copy_on_write = True
# Definiamo la chiave API
API_KEY = "inserisci la tua api-key" # Da sostituire con la propria chiave API
def get_most_popular_articles():
# la funzione recupera gli articoli più popolari dal New York Times utilizzando l'API Most Popular.
url = f"https://api.nytimes.com/svc/mostpopular/v2/viewed/{7}.json?api-key={API_KEY}"
# L'API "viewed" restituisce gli articoli più visualizzati
# Il parametro "7" indica che vogliamo gli articoli più visti negli ultimi 7 giorni
response = requests.get(url)
if response.status_code == 200:
return response.json()
else:
print(f"Errore nella richiesta: {response.status_code}")
return None
# Inizializziamo delle liste vuote per memorizzare i diversi campi degli articoli
titles = []
published_dates = []
authors = []
abstracts = []
urls = []
sections = []
abstract_lengths = []
type = []
des_facet = []
geo_facet = []
data = get_most_popular_articles() # Chiamiamo la funzione per ottenere gli articoli più popolari
if data: # Verifica se i dati sono stati recuperati con successo
for article in data['results']: # Iteriamo attraverso ogni articolo nei risultati, estraiamo i vari campi da ciascun articolo e
# aggiungiamoli agli array corrispondenti
titles.append(article['title'])
published_dates.append(article['published_date'])
authors.append(article.get('byline', 'N/A'))
abstracts.append(article['abstract'])
des_facet.append(article['des_facet'])
geo_facet.append(article['geo_facet'])
urls.append(article['url'])
sections.append(article['section'])
abstract_lengths.append(len(article['abstract'].split()))
type.append(article['type'])
# Creiamo un DataFrame pandas con i dati raccolti
nyt_df = pd.DataFrame({
'title': titles,
'published_date': published_dates,
'author': authors,
'abstract': abstracts,
'url': urls,
'section': sections,
'abstract_length': abstract_lengths,
'type': type,
'des_facet': des_facet,
'geo_facet': geo_facet
})
nyt_df.head()
| title | published_date | author | abstract | url | section | abstract_length | type | des_facet | geo_facet | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A Most Sensitive Subject in the White House: W... | 2025-05-07 | By Shawn McCreesh | Mrs. Trump has spent fewer than 14 days at the... | https://www.nytimes.com/2025/05/07/us/politics... | U.S. | 20 | Article | [White House Building (Washington, DC), United... | [] |
| 1 | The $200 Billion Gamble: Bill Gates’s Plan to ... | 2025-05-08 | By David Wallace-Wells | In a wide-ranging interview, he explains his d... | https://www.nytimes.com/2025/05/08/magazine/bi... | Magazine | 25 | Article | [Foreign Aid, Philanthropy, Developing Countri... | [] |
| 2 | Who Is Pope Leo XIV? | 2025-05-08 | By Elisabetta Povoledo, Jason Horowitz, Emma B... | Here’s what to know about the first American p... | https://www.nytimes.com/2025/05/08/world/europ... | World | 18 | Article | [Popes, Cardinals (Roman Catholic Prelates), C... | [Rome (Italy), United States, Chicago (Ill)] |
| 3 | Kennedy Swims in Washington Creek That Flows W... | 2025-05-12 | By Chris Cameron | Robert F. Kennedy Jr., the health secretary, s... | https://www.nytimes.com/2025/05/12/us/politics... | U.S. | 21 | Article | [Water Pollution, United States Politics and G... | [Washington (DC)] |
| 4 | India Strikes Pakistan but Is Said to Have Los... | 2025-05-06 | By Mujib Mashal, Hari Kumar and Salman Masood | Officials and witnesses said that at least two... | https://www.nytimes.com/2025/05/06/world/asia/... | World | 24 | Article | [War and Armed Conflicts, Defense and Military... | [India, Pakistan, Kashmir, Kashmir and Jammu (... |
Archive API
La sezione Archive API permette di accedere agli articoli del New York Times specificando un mese e un anno a partire dal 1851. Questa API è molto interessante in quanto permette di accedere a un gran numero di articoli.
Il codice seguente restituisce gli articoli di Ottobre 2023.
def get_nyt_archive_articles(year, month, api_key):
# la funzione recupera gli articoli dall'Archive API specifici per un mese e un anno e restituisce un DataFrame.
url = f"https://api.nytimes.com/svc/archive/v1/{year}/{month}.json?api-key={api_key}"
response = requests.get(url)
if response.status_code == 200: #
articles = response.json().get("response", {}).get("docs", [])
# Creiamo del DataFrame
df_ottobre_2023 = pd.DataFrame([{
'title': art.get("headline", {}).get("main", "N/A"),
'section': art.get("section_name", "N/A"),
'keywords': [kw["value"] for kw in art.get("keywords", [])],
'word_count': art.get("word_count", "N/A"),
'document_type': art.get("document_type", "N/A"),
'pub_date': art.get("pub_date", "N/A"),
'snippet': art.get("snippet", "N/A")
} for art in articles])
return df_ottobre_2023
else:
# In caso di errore nella richiesta, stampa un messaggio con il codice di stato
print(f"Errore nella richiesta API per {year}-{month}: {response.status_code}")
return None
# Definiamo i parametri necessari per la richiesta
API_KEY = "inserisci la tua api-key" # Chiave API per l'autenticazione
year, month = 2023, 10 # Anno e mese specifici (Ottobre 2023)
# Chiamata alla funzione per ottenere gli articoli di Ottobre 2023
df_ottobre_2023 = get_nyt_archive_articles(year, month, API_KEY)
df_ottobre_2023.head()
| title | section | keywords | word_count | document_type | pub_date | snippet | |
|---|---|---|---|---|---|---|---|
| 0 | Senate Democrat Threatens to Block More of Mil... | U.S. | [Egypt, Human Rights and Human Rights Violatio... | 681 | article | 2023-10-01T00:06:00+0000 | The new chairman of the Senate Foreign Relatio... |
| 1 | How Each Member Voted on the Senate Stopgap Sp... | U.S. | [Shutdowns (Institutional), Senate, Federal Bu... | 0 | multimedia | 2023-10-01T00:06:25+0000 | The Senate overwhelmingly passed a bill to fun... |
| 2 | What Does a Russia-Leaning Party Win in an E.U... | World | [Slovakia, Politics and Government, Elections,... | 1269 | article | 2023-10-01T00:18:47+0000 | In much of Europe, the election in Slovakia wa... |
| 3 | Police Chief Who Ordered Raid on Kansas Newspa... | U.S. | [Newspapers, Marion County Record (Newspaper),... | 623 | article | 2023-10-01T00:47:45+0000 | Gideon Cody, who orchestrated a widely critici... |
| 4 | Chris Snow, Hockey Executive Who Publicly Face... | Sports | [Snow, Chris, Deaths (Obituaries), Hockey, Ice... | 729 | article | 2023-10-01T01:38:51+0000 | The assistant general manager of the Calgary F... |
Article Search API
La sezione Article Search API consente di filtrare i dati secondo Keywords. E' necessario specificare una query e, qualora volessi ottenere informazioni più specifiche, puoi affinare la tua ricerca inserendo filtri e sfaccettature.
Il codice di seguito filtra e restituisce gli articoli contenenti la query Gaza.
import time # Importiamo time per gestire i ritardi tra le richieste API
def get_nyt_articles(query, api_key):
# Funzione che recupera articoli dal New York Times specifici per una query tramite l'API Article Search
base_url = "https://api.nytimes.com/svc/search/v2/articlesearch.json"
all_articles = [] # Lista vuota che conterrà tutti gli articoli recuperati
page_limit = 10 # Impostiamo un limite al numero di pagine da recuperare per:
# - Evitare di superare i limiti dell'API
# - Controllare il volume di dati recuperati
# - Ridurre i tempi di esecuzione
for page in range(page_limit):
params = { # i parametri sono:
"q": query, # La query di ricerca (es. "Gaza")
"page": page, # Il numero di pagina per la paginazione
"api-key": api_key # La chiave API per l'autenticazione
}
response = requests.get(base_url, params=params)
if response.status_code == 200:
data = response.json()
articles = data.get("response", {}).get("docs", [])
if not articles:
break
all_articles.extend(articles)
time.sleep(6) # Aggiunge un ritardo di 6 secondi tra le richieste per rispettare i limiti dell'API - circa 10 richieste al minuto (una ogni 6 secondi)
else:
# Stampa un messaggio di errore se la richiesta non è andata a buon fine
print(f"Errore nella richiesta API (pagina {page}): {response.status_code}")
break
return all_articles
API_KEY = "inserisci la tua api-key" # da sostituire con la propria api-key
# Inizializziamo le liste vuote per memorizzare i dati degli articoli
titles = []
sections = []
keywords = []
word_counts = []
document_types = []
pub_dates = []
snippets = []
urls = []
query = "Gaza" # definiamo la query
articles = get_nyt_articles(query, API_KEY) # Ottieniamo gli articoli che hanno un match con la query
for article in articles:
titles.append(article.get("headline", {}).get("main", "N/A"))
sections.append(article.get("section_name", "N/A"))
keywords.append([keyword["value"] for keyword in article.get("keywords", [])])
word_counts.append(article.get("word_count", 0))
document_types.append(article.get("document_type", "N/A"))
pub_dates.append(article.get("pub_date", "N/A"))
snippets.append(article.get("snippet", "N/A"))
urls.append(article.get("web_url", "N/A"))
# Creiamo un DataFrame pandas con i dati raccolti
articles_df = pd.DataFrame({
'title': titles,
'section': sections,
'keywords': keywords,
'word_count': word_counts,
'document_type': document_types,
'pub_date': pub_dates,
'snippet': snippets,
'url': urls
})
articles_df.head()
Errore nella richiesta API (pagina 5): 429
| title | section | keywords | word_count | document_type | pub_date | snippet | url | |
|---|---|---|---|---|---|---|---|---|
| 0 | In Private, Some Israeli Officers Admit That G... | World | [Israel-Gaza War (2023- ), Defense and Militar... | 1447 | article | 2025-05-13T17:00:39Z | Israel’s government has publicly dismissed war... | https://www.nytimes.com/2025/05/13/world/middl... |
| 1 | Netanyahu Warns of ‘Intensive’ Escalation in G... | World | [Israel-Gaza War (2023- ), Defense and Militar... | 1515 | article | 2025-05-05T10:11:26Z | Prime Minister Benjamin Netanyahu said that a ... | https://www.nytimes.com/2025/05/05/world/europ... |
| 2 | Israel Takes New Territory in Gaza, Squeezing ... | World | [Israel-Gaza War (2023- ), Hamas, United Natio... | 845 | article | 2025-04-02T09:33:17Z | Prime Minister Benjamin Netanyahu said Israel ... | https://www.nytimes.com/2025/04/02/world/middl... |
| 3 | Gaza Truce Could End in Days, With No Extensio... | World | [International Relations, Israel-Gaza War (202... | 1069 | article | 2025-02-24T11:03:23Z | Less than a week before it expires, Israel and... | https://www.nytimes.com/2025/02/24/world/middl... |
| 4 | Coffee, Juice, Shawarma: Tiny Traces of Normal... | World | [Israel-Gaza War (2023- ), Gaza Strip, Shortag... | 1398 | article | 2024-11-18T10:15:57Z | Most people in the enclave are struggling just... | https://www.nytimes.com/2024/11/18/world/middl... |
API New York Times Python: pynytimes
pynytimes è una libreria python disponibile su Github che permette di facilitare l'accesso alle APIs del New York Times. Se vuoi, puoi consultare la documentazione ufficiale.
Per poter usare pynytimes è necessario installare la libreria inserendo nel terminale:
pip install --upgrade pynytimes(Mac e Linux)
python -m pip install --upgrade pynytimes(Windows)
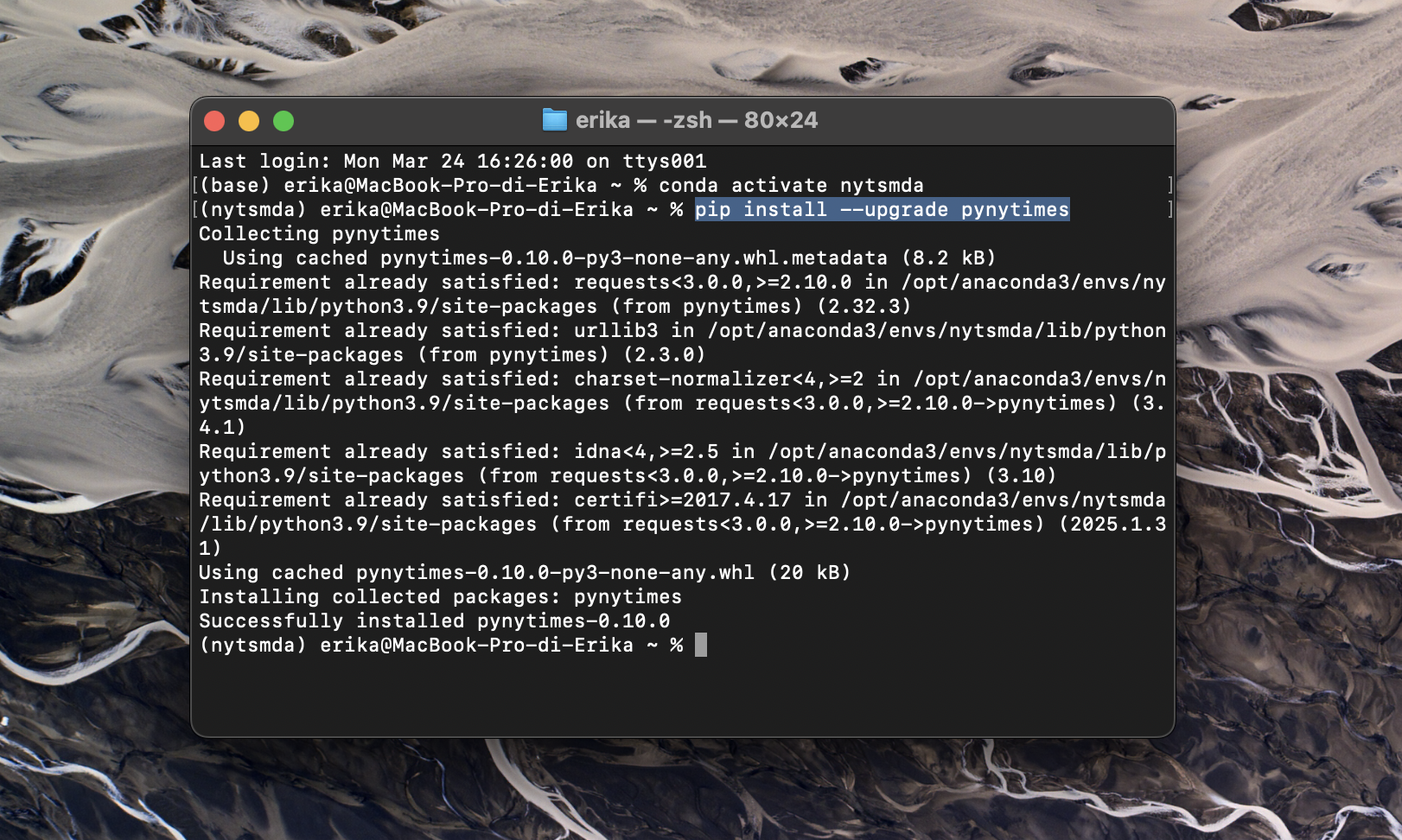
Procediamo con il codice:
from pynytimes import NYTAPI # importiamo la libreria NYTAPI
import pandas as pd # importiamo pandas (abbreviato pd) per la manipolazione dei dati in formato tabellare
nyt = NYTAPI("inserisci la tua api-key", parse_dates=True)
# parse_dates=True indica che la libreria pynytimes convertirà automaticamente le date fornite dall'API del New York Times
# in oggetti datetime di Python.
# ottiene gli articoli più condivisi su Facebook negli ultimi 30 giorni:
most_shared_facebook = nyt.most_shared(
days = 30,
method = "facebook"
)
# crea il dataframe:
most_shared_facebook_df = pd.DataFrame(most_shared_facebook)
most_shared_facebook_df.head()
| uri | url | id | asset_id | source | published_date | updated | section | subsection | nytdsection | ... | byline | type | title | abstract | des_facet | org_facet | per_facet | geo_facet | media | eta_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | nyt://article/0887c3d2-2a0f-5118-a5bb-40499adf... | https://www.nytimes.com/2025/04/14/us/harvard-... | 100000010109814 | 100000010109814 | New York Times | 2025-04-14 | 2025-04-25 00:04:48 | U.S. | u.s. | ... | By Vimal Patel | Article | Trump Administration Will Freeze $2 Billion Af... | Federal officials said they would freeze the m... | [United States Politics and Government, Presid... | [Harvard University] | [Trump, Donald J] | [] | [{'type': 'image', 'subtype': 'photo', 'captio... | 0 | |
| 1 | nyt://article/b80fd4cf-eddb-5840-884c-6426f377... | https://www.nytimes.com/2025/05/08/opinion/tru... | 100000010145026 | 100000010145026 | New York Times | 2025-05-08 | 2025-05-10 22:06:01 | Opinion | opinion | ... | By Steven Levitsky, Lucan Way and Daniel Ziblatt | Article | How Will We Know When We Have Lost Our Democracy? | And how exactly can we tell whether America ha... | [Authoritarianism (Theory and Philosophy), Dem... | [Republican Party] | [Trump, Donald J] | [] | [{'type': 'image', 'subtype': 'photo', 'captio... | 0 | |
| 2 | nyt://article/6091f5e9-dc7d-542f-8889-affa52d8... | https://www.nytimes.com/2025/05/08/us/pope-leo... | 100000010158620 | 100000010158620 | New York Times | 2025-05-08 | 2025-05-10 09:02:47 | U.S. | u.s. | ... | By Richard Fausset and Robert Chiarito | Article | New Pope Has Creole Roots in New Orleans | His ancestry, traced to a historic enclave of ... | [Popes, Genealogy, Black People, Race and Ethn... | [Roman Catholic Church] | [Gates, Henry Louis Jr, Leo XIV, Francis] | [New Orleans (La)] | [{'type': 'image', 'subtype': 'photo', 'captio... | 0 | |
| 3 | nyt://article/db509d9b-d1dd-5753-be0a-9e09f170... | https://www.nytimes.com/2025/04/17/us/politics... | 100000010116503 | 100000010116503 | New York Times | 2025-04-17 | 2025-05-01 02:19:31 | U.S. | Politics | u.s. | ... | By Annie Karni | Article | A Startling Admission From a G.O.P. Senator: ‘... | Lisa Murkowski, a longtime senator from Alaska... | [United States Politics and Government] | [Republican Party, Senate] | [Murkowski, Lisa, Trump, Donald J] | [Alaska, United States] | [{'type': 'image', 'subtype': 'photo', 'captio... | 0 |
| 4 | nyt://article/1d41dfc3-6337-5925-bc4d-9ce3ef94... | https://www.nytimes.com/2025/04/16/science/ast... | 100000010111788 | 100000010111788 | New York Times | 2025-04-16 | 2025-04-18 21:37:23 | Science | science | ... | By Carl Zimmer | Article | Astronomers Detect a Possible Signature of Lif... | Further studies are needed to determine whethe... | [Extraterrestrial Life, Space and Astronomy, P... | [Cambridge University, Astrophysical Journal L... | [] | [] | [{'type': 'image', 'subtype': 'photo', 'captio... | 0 |
5 rows × 22 columns
Estrazione dei dati e analisi
Ora che abbiamo acquisito i dati, possiamo iniziare a esplorare cosa possiamo ottenere da un'analisi degli stessi.
Numero di articoli per sezione
Focalizzandoci sul dataset relativo alle notizie di ottobre 2023, la prima cosa che faremo è plottare il numero di articoli per ciascuna sezione. Questo ci permetterà di capire quali sono le sezioni più influenti e di maggiore copertura mediatica.
import matplotlib.pyplot as plt # Importiamo la libreria per creare grafici
# calcoliamo il numero di articoli per ogni sezione (colonna 'section') utilizzando value_counts()
section_counts = df_ottobre_2023['section'].value_counts()
# creiamo un bar plot in cui l'asse x saranno le etichette delle sezioni, l'asse y i conteggi degli articoli per ogni sezione
plt.figure(figsize=(10, 6))
section_counts.plot(kind='bar', color='blue')
plt.title("Numero di articoli per sezione (10/2023)")
plt.xlabel("Sezioni")
plt.ylabel("Numero di articoli")
plt.xticks(rotation=90)
plt.tight_layout() # Ottimizziamo la disposizione degli elementi del grafico per evitare sovrapposizioni
plt.show()

Keywords più comuni
È facile notare che le sezioni con il maggior numero di articoli sono U.S. (un risultato prevedibile, considerando che il New York Times è un giornale statunitense) e World (anche questo non sorprende, dato che ottobre 2023 è stato il mese in cui il conflitto Israelo-Palestinese ha raggiunto un picco di intensità tale da portare alla tragica situazione attuale). Tuttavia, questi dati da soli non ci forniscono molte informazioni significative. Per approfondire, vediamo quali sono le parole chiave più comuni relative allo stesso mese.
from collections import Counter # Importiamo Counter per contare facilmente la frequenza degli elementi
# cerchiamo le keywords più comuni
keywords_flat = [keyword for sublist in df_ottobre_2023['keywords'] for keyword in sublist]
keyword_counts = Counter(keywords_flat)
most_common_keywords = keyword_counts.most_common(10)
# Creiamo un grafico a barre orizzontale che mostra le keywords più usate negli articoli
plt.barh([keyword[0] for keyword in most_common_keywords], [keyword[1] for keyword in most_common_keywords], color='blue')
plt.title('Keywords più comuni')
plt.xlabel('Frequenza')
plt.ylabel('Keyword')
plt.show()

Non sorprende che le parole chiave più comuni riguardino il conflitto Israelo-Palestinese.
Con questi dati a disposizione e consapevoli del fatto che il conflitto è ancora in corso, possiamo condurre un'analisi per verificare se l'attenzione mediatica alle notizie sul conflitto rimane costante nel tempo o se, al contrario, diminuisce progressivamente. In altre parole, analizzeremo se la copertura delle notizie segue un andamento simile a quello dei trend, con picchi iniziali di interesse e una discesa successiva.
Andamento delle notizie sul conflitto Israelo-Palestinese
Per condurre la nostra analisi sull'andamento delle notizie inerenti il conflitto Israelo-Palestinese, scegliamo dei mesi densi di avvenimenti, che possano avere la stessa rilevanza mediatica di Ottobre 2023, periodo in cui il conflitto ha ricevuto grande attenzione.
Creiamo nuovi dataset relativi ai mesi di Dicembre 2023, Gennaio 2024, Maggio 2024, Giugno 2024, Ottobre 2024, Gennaio 2025 e Marzo 2024. Questi mesi sono stati scelti perché segnano momenti chiave nello sviluppo del conflitto, come fasi di tregua, ripresa delle ostilità o eventi che hanno avuto una particolare risonanza a livello mediatico e internazionale.
# avendo già definito la funzione per accedere ad Archive API, basta richiamarla e definirne i parametri
year, month = 2023, 12
df_dicembre_2023 = get_nyt_archive_articles(year, month, API_KEY)
df_dicembre_2023.head()
| title | section | keywords | word_count | document_type | pub_date | snippet | |
|---|---|---|---|---|---|---|---|
| 0 | Donald Trump Still Wants to Kill Obamacare. Why? | Opinion | [Patient Protection and Affordable Care Act (2... | 880 | article | 2023-12-01T00:00:09+0000 | Is this really about policy, or is it personal? |
| 1 | 6 Former Jail Officers Charged in Death of Wes... | U.S. | [Prisons and Prisoners, Deaths (Fatalities), A... | 673 | article | 2023-12-01T00:02:56+0000 | Prosecutors said the former corrections office... |
| 2 | Israel Knew Hamas’s Attack Plan More Than a Ye... | World | [Israel-Gaza War (2023- ), Israel, Defense and... | 1582 | article | 2023-12-01T00:16:08+0000 | A blueprint reviewed by The Times laid out the... |
| 3 | Judge Halts TikTok Ban in Montana | Business Day | [TikTok (ByteDance), Beijing Bytedance Technol... | 1030 | article | 2023-12-01T00:16:41+0000 | TikTok, which is owned by the Chinese company ... |
| 4 | Kissinger Had the Ear of Presidents. He Had Th... | U.S. | [United States Politics and Government, Presid... | 962 | article | 2023-12-01T00:27:49+0000 | In his decades in politics, the statesman advi... |
year, month = 2024, 1
df_gennaio_2024 = get_nyt_archive_articles(year, month, API_KEY)
df_gennaio_2024.head()
| title | section | keywords | word_count | document_type | pub_date | snippet | |
|---|---|---|---|---|---|---|---|
| 0 | PGA Tour and Saudi-Backed LIV Extend Deadline ... | Business Day | [Golf, Mergers, Acquisitions and Divestitures,... | 558 | article | 2024-01-01T00:25:32+0000 | The tentative deal for the men’s golf circuits... |
| 1 | Something to Whistle | Crosswords & Games | [Crossword Puzzles, Games] | 855 | article | 2024-01-01T00:32:06+0000 | Harry Zheng makes his New York Times debut. |
| 2 | U.S. Helicopters Sink 3 Houthi Boats in Red Se... | World | [Israel-Gaza War (2023- ), Ships and Shipping,... | 1218 | article | 2024-01-01T00:53:23+0000 | Iranian-backed Houthi gunmen from Yemen had fi... |
| 3 | In Times Square, Hundreds of Thousands Ring In... | New York | [New Year, Demonstrations, Protests and Riots,... | 608 | article | 2024-01-01T02:09:45+0000 | New Year’s celebrations took place as proteste... |
| 4 | Quotation of the Day: In a Jewish-Arab School,... | Corrections | [] | 36 | article | 2024-01-01T03:59:09+0000 | Quotation of the Day for Monday, January 1, 2024. |
year, month = 2024, 5
df_maggio_2024 = get_nyt_archive_articles(year, month, API_KEY)
df_maggio_2024.head()
| title | section | keywords | word_count | document_type | pub_date | snippet | |
|---|---|---|---|---|---|---|---|
| 0 | What Happened at the Trump Trial on Tuesday | New York | [New York State Criminal Case Against Trump (7... | 0 | multimedia | 2024-05-01T00:12:20+0000 | Donald Trump was fined and warned of jail time... |
| 1 | Even Celebrities Don’t Know How to Ask Their F... | Style | [Semaglutide (Drug), Ozempic (Drug), Weight, S... | 590 | article | 2024-05-01T00:16:54+0000 | When Barbra Streisand posted a comment on soci... |
| 2 | Law Firm Defending Trump Seeks to Withdraw Fro... | U.S. | [Trump, Donald J, Legal Profession, Suits and ... | 806 | article | 2024-05-01T01:05:49+0000 | The firm, LaRocca Hornik, has represented Dona... |
| 3 | Transcript: Ezra Klein Interviews Hannah Ritchie | Podcasts | [Ritchie, Hannah (1993- )] | 11083 | article | 2024-05-01T01:06:41+0000 | The April 30, 2024, episode of “The Ezra Klein... |
| 4 | Albuquerque School’s Staff on Leave After Drag... | U.S. | [Education (K-12), Proms, Drag (Performance), ... | 603 | article | 2024-05-01T01:06:48+0000 | Albuquerque Public Schools in New Mexico also ... |
year, month = 2024, 6
df_giugno_2024 = get_nyt_archive_articles(year, month, API_KEY)
df_giugno_2024.head()
| title | section | keywords | word_count | document_type | pub_date | snippet | |
|---|---|---|---|---|---|---|---|
| 0 | ‘Doctor Who’ Episode 5 Recap: Bursting the Bubble | Arts | [Television, YouTube.com, Doctor Who (TV Progr... | 1069 | article | 2024-06-01T00:00:08+0000 | The Doctor saves a rich wannabe vlogger from b... |
| 1 | Ohio Legislature Passes Bill Ensuring Biden’s ... | U.S. | [Presidential Election of 2024, State Legislat... | 491 | article | 2024-06-01T00:15:09+0000 | The bill, which Gov. Mike DeWine, a Republican... |
| 2 | Florida Deputy Who Fatally Shot Airman Is Fired | U.S. | [Police Brutality, Misconduct and Shootings, M... | 542 | article | 2024-06-01T01:02:38+0000 | The Okaloosa County Sheriff’s Office said that... |
| 3 | Trump and Allies Assail Conviction With Faulty... | U.S. | [Federal Criminal Case Against Trump (Document... | 1769 | article | 2024-06-01T01:07:56+0000 | After former President Donald J. Trump was fou... |
| 4 | How Trump’s Most Loyal Supporters Are Respondi... | U.S. | [Decisions and Verdicts, Conservatism (US Poli... | 1267 | article | 2024-06-01T01:12:49+0000 | Many saw in the jury’s finding a rejection of ... |
year, month = 2024, 10
df_ottobre_2024 = get_nyt_archive_articles(year, month, API_KEY)
df_ottobre_2024.head()
| title | section | keywords | word_count | document_type | pub_date | snippet | |
|---|---|---|---|---|---|---|---|
| 0 | Adams Confidant Steps Down Amid Federal Corrup... | New York | [Pearson, Timothy, Adams, Eric L, Eric Adams F... | 939 | article | 2024-10-01T00:01:59+0000 | Few people in city government were closer to M... |
| 1 | Newsom Tacks to the Middle With California in ... | U.S. | [United States Politics and Government, Presid... | 1188 | article | 2024-10-01T00:21:58+0000 | While Donald J. Trump has attacked California ... |
| 2 | Corrections: Oct. 1, 2024 | Corrections | [] | 180 | article | 2024-10-01T01:00:02+0000 | Corrections that appeared in print on Tuesday,... |
| 3 | Robert Downey Jr. Is a Novelist With a Novel M... | Theater | [Theater, Theater (Broadway), Beaumont, Vivian... | 897 | article | 2024-10-01T01:00:09+0000 | The “Oppenheimer” star makes his Broadway debu... |
| 4 | Rancher Gets 6 Months in Prison for Scheme to ... | U.S. | [Wildlife Trade and Poaching, Kyrgyzstan, Mont... | 661 | article | 2024-10-01T01:03:43+0000 | Prosecutors said the Montanan illegally used t... |
year, month = 2025, 1
df_gennaio_2025 = get_nyt_archive_articles(year, month, API_KEY)
df_gennaio_2025.head()
| title | section | keywords | word_count | document_type | pub_date | snippet | |
|---|---|---|---|---|---|---|---|
| 0 | Dartmouth College Basketball Players Halt Effo... | U.S. | [Basketball (College), Dartmouth College, Orga... | 685 | article | 2025-01-01T00:26:42+0000 | The decision to withdraw the petition appeared... |
| 1 | ‘He Saved Our Lives’: Former Hostages Recall C... | U.S. | [Carter, Jimmy, Kidnapping and Hostages, Iran,... | 1806 | article | 2025-01-01T00:44:39+0000 | The Iran hostage crisis became a symbol of a f... |
| 2 | Corrections: Jan. 1, 2025 | Corrections | [] | 279 | article | 2025-01-01T02:30:02+0000 | Corrections that appeared in print on Wednesda... |
| 3 | A Certain Tankful | Crosswords & Games | [Crossword Puzzles, Games] | 1033 | article | 2025-01-01T03:00:02+0000 | Seth Bisen-Hersh and Jeff Chen take it from th... |
| 4 | China’s Leader Nods to Economic Challenges | Business Day | [Economic Conditions and Trends, China, Gross ... | 448 | article | 2025-01-01T03:40:13+0000 | In a New Year’s address, Xi Jinping made a rar... |
year, month = 2025, 3
df_marzo_2025 = get_nyt_archive_articles(year, month, API_KEY)
df_marzo_2025.head()
| title | section | keywords | word_count | document_type | pub_date | snippet | |
|---|---|---|---|---|---|---|---|
| 0 | A Day of American Infamy | Opinion | [United States International Relations, Russia... | 923 | article | 2025-03-01T00:00:33+0000 | A dreadful moment for Ukraine, for the free wo... |
| 1 | Behind the Collision: Trump Jettisons Ukraine ... | U.S. | [United States Politics and Government, United... | 1400 | article | 2025-03-01T00:15:42+0000 | The president’s explosive Oval Office encounte... |
| 2 | Despite Efforts to Save It, a Beloved Pink Hou... | U.S. | [Demolition, Historic Buildings and Sites, Wil... | 629 | article | 2025-03-01T00:17:47+0000 | Gov. Maura Healey, lamenting the decision, cal... |
| 3 | Europe Rallies Around Zelensky After Explosive... | U.S. | [Russian Invasion of Ukraine (2022), United St... | 816 | article | 2025-03-01T00:18:14+0000 | The statements piled up on social media, offer... |
| 4 | Putin Is Ready to Carve Up the World. Trump Ju... | Opinion | [Russian Invasion of Ukraine (2022), United St... | 1378 | article | 2025-03-01T00:36:22+0000 | The talks about Ukraine were never just about ... |
Dopo aver creato i vari dataset, possiamo passare alla visualizzazione dell’andamento delle notizie sul conflitto Israelo-Palestinese. Per farlo, tracciamo dei bar plot che mostrano, giorno per giorno e per ogni mese, il numero di articoli pubblicati sull’argomento. Questo ci permetterà di osservare come è variata nel tempo l’attenzione del New York Times sull’argomento, con eventuali picchi o cali di copertura.
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Lista corretta delle keywords
keywords = [
'Palestinians',
'Hamas',
'Gaza Strip',
'Israel',
'Israel-Gaza War (2023)'
]
# Creiamo una figura con una griglia 4x2 per i grafici
fig, axes = plt.subplots(4, 2, figsize=(20, 24))
axes = axes.flatten() # Appiattisce la matrice 4x2 in un array monodimensionale
# Lista dei dataframe e dei titoli corrispondenti
dataframes = [
df_ottobre_2023, df_dicembre_2023,
df_gennaio_2024, df_maggio_2024,
df_giugno_2024, df_ottobre_2024,
df_gennaio_2025, df_marzo_2025
]
titles = [
'Articoli sul conflitto Israelo-Palestinese per giorno (Ottobre 2023)',
'Articoli sul conflitto Israelo-Palestinese per giorno (Dicembre 2023)',
'Articoli sul conflitto Israelo-Palestinese per giorno (Gennaio 2024)',
'Articoli sul conflitto Israelo-Palestinese per giorno (Maggio 2024)',
'Articoli sul conflitto Israelo-Palestinese per giorno (Giugno 2024)',
'Articoli sul conflitto Israelo-Palestinese per giorno (Ottobre 2024)',
'Articoli sul conflitto Israelo-Palestinese per giorno (Gennaio 2025)',
'Articoli sul conflitto Israelo-Palestinese per giorno (Marzo 2025)'
]
# Ciclo per creare ogni grafico nel suo rispettivo subplot
for i, (df, title) in enumerate(zip(dataframes, titles)):
# Controllo preliminare sulle colonne
if 'keywords' not in df.columns or 'pub_date' not in df.columns:
print(f"'{title}' manca delle colonne richieste ('keywords', 'pub_date').")
continue
# Filtriamo gli articoli che contengono almeno una keyword
mask = df['keywords'].apply(lambda kw_list: any(k in kw_list for k in keywords))
filtered_articles = df[mask].copy() # Creiamo una copia esplicita per evitare SettingWithCopyWarning
if filtered_articles.empty:
axes[i].text(0.5, 0.5, 'Nessun dato disponibile', ha='center', va='center', fontsize=12, color='red')
axes[i].set_title(title)
axes[i].set_xticks([])
axes[i].set_yticks([])
continue
# Estraiamo solo la data (senza orario) e contiamo gli articoli per giorno
filtered_articles.loc[:, 'date'] = pd.to_datetime(filtered_articles['pub_date'], errors='coerce').dt.date
articles_count = filtered_articles.groupby('date').size().reset_index(name='count')
if articles_count.empty:
axes[i].text(0.5, 0.5, 'Nessun dato dopo raggruppamento', ha='center', va='center', fontsize=12, color='red')
axes[i].set_title(title)
axes[i].set_xticks([])
axes[i].set_yticks([])
continue
# Creiamo il grafico nel subplot corrispondente
sns.barplot(x='date', y='count', data=articles_count, ax=axes[i])
# Personalizziamo il grafico
axes[i].set_title(title)
axes[i].set_xlabel('Data')
axes[i].set_ylabel('Numero di articoli')
axes[i].tick_params(axis='x', rotation=45)
# Aggiustiamo il layout per evitare sovrapposizioni
plt.tight_layout()
plt.show()

Nei grafici si notano alcuni picchi in corrispondenza di giornate specifiche, ma l’andamento generale – fatta eccezione per i mesi di maggio e ottobre 2024 – risulta in calo rispetto a ottobre 2023.
Per avere una visione più compatta e immediata dell’evoluzione nel tempo, creiamo uno scatter plot che mostra il numero totale di articoli pubblicati per ciascun mese:
import matplotlib.pyplot as plt # libreria che ci serve per creare i grafici
import pandas as pd # libreria per la manipolazione dei dati in formato tabellare
import matplotlib.dates as mdates # Modulo di Matplotlib per gestire e formattare date negli assi temporali dei grafici
from datetime import datetime # Oggetto datetime usato per gestire e convertire date e orari
import numpy as np # Libreria per operazioni numeriche avanzate
# Lista dei dataframe e delle date corrispondenti
dataframes = [
df_ottobre_2023, df_dicembre_2023,
df_gennaio_2024, df_maggio_2024,
df_giugno_2024, df_ottobre_2024,
df_gennaio_2025, df_marzo_2025
]
# Convertiamo i nomi in date di riferimento per il grafico (primo giorno di ogni mese)
date_labels = [
datetime(2023, 10, 1), datetime(2023, 12, 1),
datetime(2024, 1, 1), datetime(2024, 5, 1),
datetime(2024, 6, 1), datetime(2024, 10, 1),
datetime(2025, 1, 1), datetime(2025, 3, 1)
]
# Calcoliamo il numero totale di articoli per ogni mese
article_counts = []
for df in dataframes:
# Filtra articoli che contengono almeno una keyword
filtered_articles = df[df['keywords'].apply(lambda kw_list: any(k in kw_list for k in keywords))]
article_counts.append(len(filtered_articles))
# Creiamo il grafico scatter
plt.figure(figsize=(15, 8))
# Aggiungiamo una dimensione variabile ai punti in base al numero di articoli
sizes = [count * 2 for count in article_counts] # Moltiplichiamo per 2 per rendere i punti più visibili
# Scatter plot con dimensione variabile
plt.scatter(date_labels, article_counts, s=sizes, alpha=0.7, c=range(len(date_labels)), cmap='viridis')
# Personalizziamo l'asse x per mostrare le date in formato mese-anno
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%b %Y'))
plt.gca().xaxis.set_major_locator(mdates.MonthLocator(interval=1))
# Aggiungiamo le linee di collegamento tra i punti
plt.plot(date_labels, article_counts, 'k--', alpha=0.3)
# Aggiungiamo le etichette ai punti
for i, (date, count) in enumerate(zip(date_labels, article_counts)):
plt.annotate(f"{count} articoli",
xy=(date, count),
xytext=(5, 10),
textcoords="offset points",
fontsize=9,
bbox=dict(boxstyle="round,pad=0.3", fc="white", ec="gray", alpha=0.8))
# Titolo e etichette
plt.title('Articoli sul conflitto Israelo-Palestinese per periodo (Ottobre 2023 - Marzo 2025)', fontsize=14)
plt.xlabel('Periodo', fontsize=12)
plt.ylabel('Numero di articoli', fontsize=12)
plt.grid(True, alpha=0.3)
# Rotiamo le etichette sull'asse x per una migliore leggibilità
plt.xticks(rotation=45)
# Aggiungiamo una colorbar per indicare la progressione temporale
cbar = plt.colorbar(ticks=[])
cbar.set_label('Progressione temporale')
plt.tight_layout()
plt.show()
# Visualizziamo a schermo una tabella con il riassunto dei dati per riferimento
print("Riassunto dei dati:")
print("-" * 50)
print(f"{'Periodo':<15} | {'Numero di articoli':<20}")
print("-" * 50)
for date, count in zip(date_labels, article_counts):
print(f"{date.strftime('%b %Y'):<15} | {count:<20}")

Riassunto dei dati: -------------------------------------------------- Periodo | Numero di articoli -------------------------------------------------- Oct 2023 | 570 Dec 2023 | 286 Jan 2024 | 240 May 2024 | 274 Jun 2024 | 164 Oct 2024 | 319 Jan 2025 | 156 Mar 2025 | 117
Basandoci sull'analisi effettuata possiamo affermare che le notizie si comportano esattamente come i trend. In particolare, nell'analisi condotta, possiamo notare un picco coincidente all'inizio del conflitto e una discesa molto netta con l'avanzare dei mesi: il mese di Marzo, che segna la ripresa delle ostilità dopo la tregua sancita a Gennaio, è infatti il più povero di articoli sul conflitto, nonostante sia denso di avvenimenti importanti. Dall’analisi dei dati emerge chiaramente che anche le notizie seguono un comportamento simile a quello dei trend: all’inizio c’è un picco di attenzione, che poi cala progressivamente nel tempo. Nel nostro caso, il numero di articoli raggiunge il massimo all'inizio del conflitto, per poi diminuire mese dopo mese. È interessante notare come, nonostante a marzo si sia registrata una ripresa delle ostilità dopo la tregua di gennaio, quel mese risulta essere tra i meno coperti a livello giornalistico. Questo conferma come anche l'interesse delle testate giornalistiche nella diffusione dell'informazione non dipenda sempre dall'importanza intrinseca di un avvenimento, ma spesso segua le dinamiche tipiche delle tendenze mediatiche.
Conclusioni
In questo tutorial, dopo una breve introduzione alla storia del New York Times e alla sua transizione dal formato cartaceo al digitale, ci si è focalizzati sull'esplorazione delle API messe a disposizione dal quotidiano attraverso la sezione developer. È stato illustrato come registrarsi alla piattaforma per ottenere le chiavi di accesso, come configurare un ambiente virtuale e come effettuare correttamente le richieste alle varie API disponibili.
Successivamente, è stato presentato l’utilizzo della libreria pynytimes, disponibile su GitHub, che semplifica notevolmente l’interazione con le API del New York Times, rendendo il processo più rapido e accessibile anche a chi ha meno familiarità con le chiamate HTTP dirette.
Una volta creati i dataset tramite queste API, si è passati all’analisi dei dati, concentrandosi in particolare sull’andamento delle notizie legate al conflitto israelo-palestinese. L'analisi ha evidenziato un andamento decrescente nel tempo della copertura mediatica, confermando come anche le notizie seguano il tipico calo d'interesse associato ai trend.
Il lavoro svolto ha dimostrato come, grazie alle API, sia possibile accedere e interrogare grandi quantità di dati in modo sistematico, mettendo in evidenza il loro enorme potenziale come strumento per un accesso strutturato e automatizzato all’informazione.
Referenze
- https://www.nytimes.com
- https://developer.nytimes.com
- https://virtualenv.pypa.io/en/latest/installation.html
- https://www.anaconda.com/docs/getting-started/miniconda/install
- https://www.anaconda.com/docs/getting-started/anaconda/install
- https://www.geeksforgeeks.org/how-to-create-and-use-env-files-in-python/
- https://it.wikipedia.org/wiki/The_New_York_Times