L'immagine social di Napoli: sulle tracce della stigmatizzazione mediatica di una città.
| Strumenti adoperati | |
|---|---|
| Raccolta dati | Analisi dati |
|
Instagram 4CAT Zeeschuimer Docker Vedi la sezione Costruzione per maggiori informazioni |
Kaggle Notebook Python (librerie principali: torch, matplot, pandas, numpy, spacy, nltk, transformers) |
| Corso di Sociologia digitale (AA 2024/25) a cura di Davide Bennato e Guido Anselmi | |
| Corso di Linguistica computazionale (AA 2024/25) a cura di Misael Mongiovì | |
| Università di Catania, Aprile 2025 | |
Clicca qui per il codice completo
Successivamente alla pandemia da Covid-19, Napoli ha registrato un sensibile aumento dei flussi turistici in entrata – con oltre 5 milioni di visitatori annui, secondo dati ENIT – diventando una tra le più ambite mete del sud Italia.
Questo fenomeno trova ovviamente riscontro sulle piattaforme social, prima fra tutte Instagram, principale spazio virtuale in cui agisce la costruzione dal basso delle narrazioni e delle immagini nel mondo contemporaneo.
Il linguaggio turistico è un potente strumento capace di plasmare la realtà, pertanto questo studio si occupa di ponderare l'influsso di quest'ultimo sull'identità della città partenopea attraverso gli strumenti del data-mining e dell'analisi statistica applicata al testo.
In questo quadro, si parte da una definizione di stigmatizzazione affine all'orientamento dei Cultural Studies, ossia come di un fenomeno che cristallizza l'identità di un popolo, luogo o cultura – con accezioni tanto positive quanto negative. Lo studio esposto di seguito si propone di verificare se la stigmatizzazione mediatica persista come tendenza prevalente nei contenuti social legati a Napoli.
Per farlo si è proceduto secondo i seguenti passaggi:
- Costruzione del dataset
- Pulizia del dataset
- Sentiment analysis
- Analisi linguistica
Costruzione del dataset
Per lo studio è stato creato un profilo apposito, il meno possibile profilato. Sono state scelte 8 query da lanciare nella sezione "Per te" di Instagram: #igersnapoli, #napoletani, #napoletanità, #napoli, #napolicolera, #napolidavivere, #napolimerda, #vesuviolavalicolfuoco.
Queste sono state scelte in maniera da ottenere un dataset quanto più possibile bilanciato tra contenuti presumibilmente dispreggiativi e presumibilmente promozionali/positivi.
Per le operazioni di scraping si è fatto utilizzo dell'estensione Zeeschuimer messa a disposizione da Digital Methods sul framework open-source 4CAT. Docker è stato utilizzaro per creare un ambiente isolato, senza la necessità di installare il sistema Ubuntu, ma sfruttando un container preconfigurato.
Dal dataset risultante - in formato .ndjson - sono state selezionate solo le chiavi interessanti per lo studio: id del post, numero di like, numero di commenti, username dell'autore, se quest'ultimo è o meno un account verificato da Meta, caption, riconoscimento dell'immagine tramite Google Vision API.
Per farlo si è definita la seguente funzione:
def json_todict (file_path):
hashposts = []
with open(file_path, 'r') as file:
reader = ndjson.reader(file)
for obj in reader:
dict_select = {}
dict_select['id'] = obj['id']
dict_select['likes'] = obj['like_count']
dict_select['comments'] = obj['comment_count']
dict_select['username'] = obj['user']['username']
dict_select['verified'] = obj['user']['is_verified']
try:
caption = obj['caption']['text']
text, hashtags = caption_split(caption)
except:
text = None
hashtags = None
dict_select['text'] = text
dict_select['hashtags'] = hashtags
try:
recognition = obj['accessibility_caption']
except:
try:
recognition = obj['carousel_media'][0]['accessibility_caption']
except:
recognition = None
dict_select['image_recognition'] = recognition
hashposts.append(dict_select)
return hashpostsPulizia del dataset
Il dataset ottenuto contiene ancora post senza caption o con caption vuota e condivisioni di uno stesso post. Perciò ci si è innanzitutto premurati di eliminare le righe corrispondenti a questi casi.
Si è ottenuto così un dataset di 7584 post, da cui è stato necessario eliminare qualsiasi post che esuli dagli scopi dello studio, primariamente tutti quei post relativi al mondo del calcio.
Per individuarli si sono utilizzati dei pattern Regex del tipo
pattern = r'soccer|football'
hashtags_select = ["championsleague", "calcio", "football", "sscn", "universocalcistico", "forzanapoli"]
pattern = r'|'.join(hash for hash in hashtags_select)
Il primo è stato applicato alla colonna "image_recognition" e il secondo alla colonna "hahstags".
Sentiment Analysis
Per la sentiment analysis è stato scelto il modello preaddestrato twitter-xlm-roberta-base-sentiment (clicca qui per maggiori informazioni sul modello).
Esso è stato lanciato su tutte le caption restituendo per ognuna un label (positive/negative/neutral) e un indice da 0 a 1 che rappresenta la sicurezza con cui il modello attribuisce il label.
Poiché ai fini dello studio non interessano i post taggati con sentiment neutral, essi sono stati eliminati. Dopo aver filtrato per score=>0.6 si è ottenuta la seguente distribuzione di post con sentiment positivo e post con sentiment negativo:
num_pos num_neg
igersnapoli.ndjson 158 47
napoletani.ndjson 102 62
napoletanit�.ndjson 234 57
napoli.ndjson 78 25
napolicolera.ndjson 127 364
napolidavivere.ndjson 204 37
napolimerda.ndjson 272 300
vesuviolavalicolfuoco.ndjson 14 13
totale 1.189 905Oltre a confermare con una certa nettezza la previsione iniziale del sentiment delle singole query, la tabella sovrastante dimostra anche che il datset rispetta il crterio del bilanciamento sotto il punto di vista del sentiment.
Analisi testuale
Dopo aver effettuato un'ulteriore pulizia del dataset - filtrando per caption con più testo che emojii - è stato istanziato il modello all-mpnet-base-v2 di SentenceTransformer con cui si è calcolata la similarità tra tutti i post positivi tra loro e tutti i post negativi, ottenendo così due tensori aventi tante righe e tante colonne quanti sono rispettivamente i post con sentiment positivo e i post con sentiment negativo.
I due tensori sono stati resi sottoforma di matrici attraverso matplotlib.
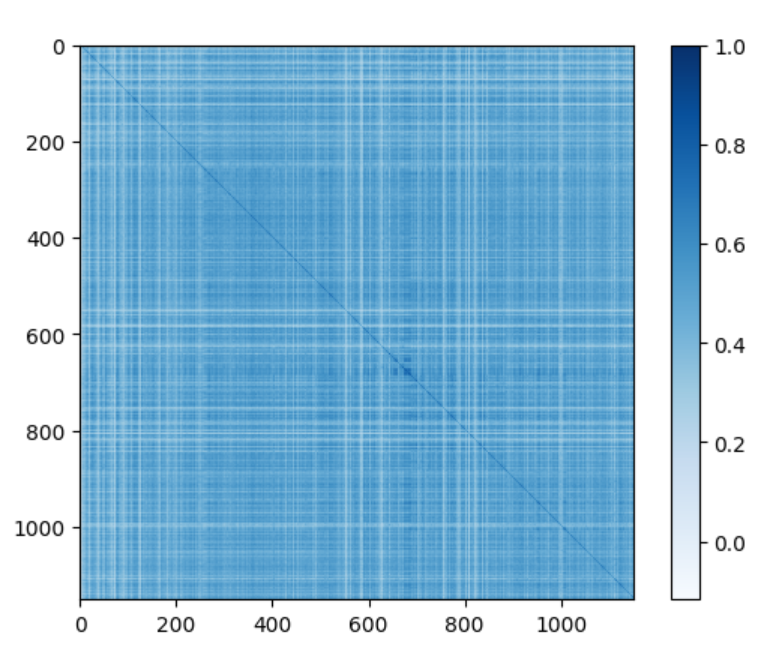
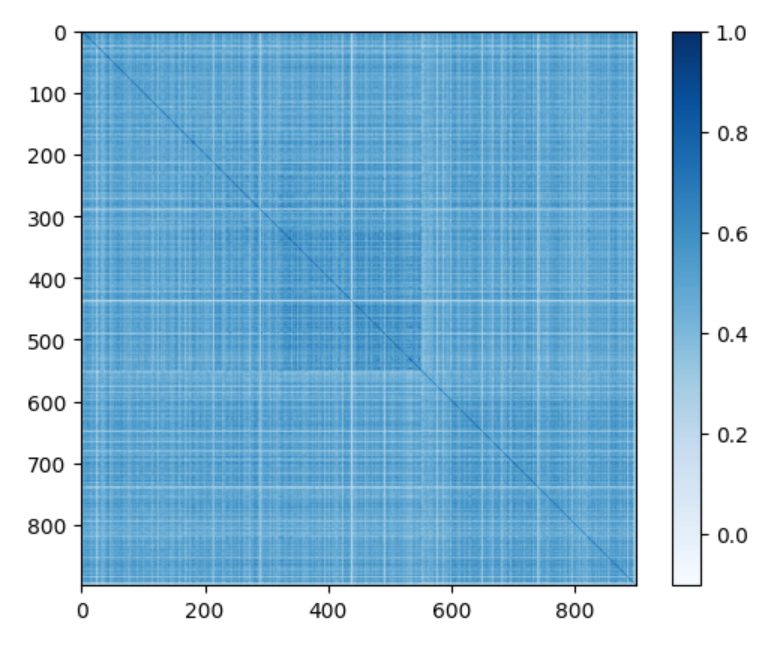
Poiché i grafici sono in grado di dare solo un'idea generale della coerenza interna dei due dataset (positivo e negativo), si è proceduto col calcolo della deviazione standard, più appropriata per un confronto lampante e scientifico.
def inner_coherence(clipped_similarity):
sim_np = clipped_similarity.cpu().numpy()
values = sim_np[sim_np != -1]
std_sim = np.std(values, ddof=0)
return std_sim[...]
Il dataset dei post con sentiment positivo hanno deviazione standard = 0.1399[...]
Il dataset dei post con sentiment positivo hanno deviazione standard = 0.1251Ciò vuol dire che tanto i post positivi, quanto quelli negativi hanno un'alta coerenza interna, dovuta certo in parte all'utilizzo dello stesso canale comunicativo - che porta con sé affordances (o culture di utilizzo) e un certo stile. Ma in parte ciò conferma la tesi iniziale: che la costruzione dell'identità della città di Napoli è intrisa di stigma, nel bene come nel male.